|
Swaminathan S K I'm a senior at the Indian Institute of Technology(IIT) Kharagpur, pursuing my Dual degree (BTech + MTech) in Computer Science and Engineering. I am truly grateful and lucky to be doing my bachelor's and master's theses under Prof. Aritra Hazra in the field of reinforcement learning and representation learning. I am an Undergraduate Researcher at the Autonomous Ground Vehicle: Autonomy and Intelligence (AGV.AI) Research Group at IIT Kharagpur under the supervision of Prof. Debashish Chakravarty. I'm currently away from my home institute on a semester-away research project program at NUS for the summer and fall semester of 2026. Here, I am working on self-supervised/un-supervised RL for real-life robotics with some awesome folks at MARMoT lab, under the guidance of Prof. Guillaume Sartoretti I spent my sophomore year summer (2024) as a visiting research student at Cognitive Learning for Vision and Robotics Lab (CLVR) at KAIST, under the guidance of Prof. Joseph J. Lim. |

|
ResearchI'm interested in reinforcement learning, multi-agent systems, robot learning and interpretability. Most of my current research work focuses on major problems faced in transfer and deployment of RL and MARL algorithms into real life robotics. I believe that resolving problems like sample-efficiency, scalability and interpretability are core to the functioning and practical application of RL in robotics. My broader research goal is essentially creating robust and safe robots with accompanying RL algorithms that can "reason" by themselves. The idea that autonomous vehicles, robots and other agents can co-exist with humanity is something that gives me a lot of motivation. Though, I believe that robots which can do tasks that humans cannot do will be more helpful in the long run! |
Publications |
|
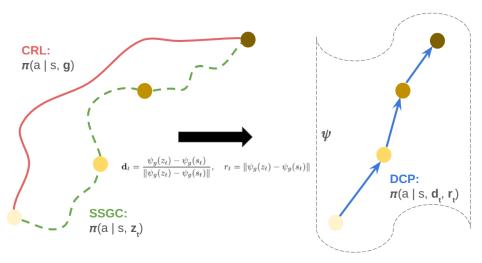
Direction-Conditioned Policies via Compositional Subgoal Scoring for Online Goal-Conditioned Reinforcement Learning
Swaminathan S K, Damiya Gondha, Theyanesh Eswaramoorthy Rajahkrishnan, Aritra Hazra ICML Workshop on Compositional Learning: Safety, Interpretability, and Agents (CompLearn), 2026 (Poster) OpenReview An online goal-conditioned RL method that conditions the actor on a learned unit direction in InfoNCE representation space rather than raw goal coordinates. We give a theoretical account via HJB direction sufficiency, a planning-invariance bound at the conditioning interface, and a controllable-subspace failure characterization. Consistent gains over Contrastive RL across nine navigation and manipulation tasks, with the largest improvements on the hardest manipulation tasks. |
|
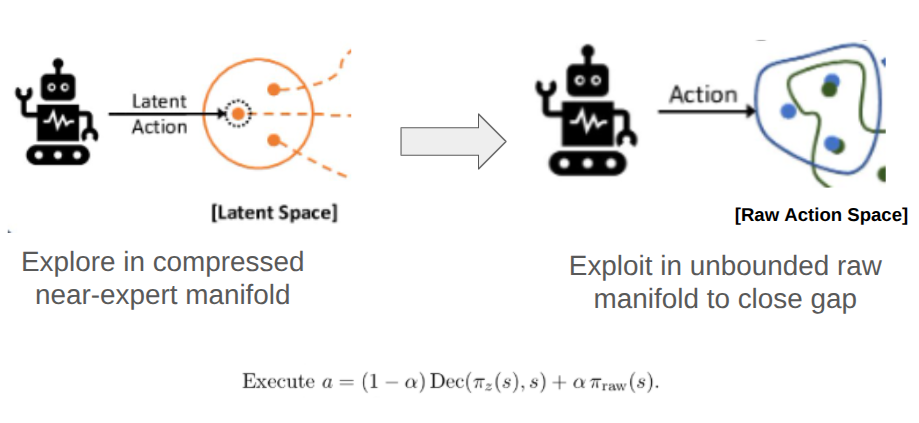
SPAARS: Safer RL Policy Alignment through Abstract Exploration and Refined Exploitation of Action Space
Swaminathan S K, Aritra Hazra arXiv preprint, 2026 arXiv / pdf A curriculum framework for offline-to-online RL that initially constrains exploration to a CVAE latent manifold for sample-efficient, safe behavioral improvement, then transfers to the raw action space — breaking the exploitation ceiling imposed by the decoder's reconstruction loss. An advantage-gated mode selection mechanism grounded in the Option-Critic termination gradient replaces global α schedules with per-state decisions. Standalone SPAARS exceeds the offline IQL baseline on D4RL locomotion tasks. |
Projects |

|
LMPC: Safe Multi-Robot Navigation
Mobile Ground Robots, AGV.AI (Inter IIT Tech Meet 13.0 — Solo Gold, IIT Bombay, 2024) A general safe navigation framework for multi-robot mobile ground systems. Built for and awarded Solo Gold at Inter IIT Tech Meet 13.0 hosted by IIT Bombay (2024). |

|
Rustee
Mobile Ground Robots, IIT Kharagpur A mobile ground robot with a vertical actuator designed to scan racks. Built for Inter IIT Tech Meet 14.0 (2025) as a cross-team collaboration at IIT Kharagpur, with contributors from AGV.AI and across campus. |

|
F1Tenth Autonomous Racing
Mobile Ground Robots, AGV.AI (1st in prelims worldwide, RoboRacer SimLeague @ ICRA 2025) ICRA 2025 results; CDC 2024 results An autonomous racing pipeline implementation, deployed in the F1Tenth / RoboRacer SimLeague: 1st in prelims and 9th in finals worldwide at ICRA 2025; 8th in prelims worldwide at CDC 2024. |
|
Website template from Jon Barron |